
Visual Software Agent: A Realistic Face-to-Face Style Interface connected with WWW/Netscape
Hiroshi Dohi and Mitsuru Ishizuka
Dept. of Information and Communication Engineering,
School of Engineering, University of Tokyo
7-3-1, Hongo, Bunkyo-ku, Tokyo 113, JAPAN
E-mail: dohi@miv.t.u-tokyo.ac.jp
This paper describes the Visual Software Agent (VSA) interface connected with a voice-controlled Netscape. VSA is an Internet-based interface agent with rocking realistic face and speech dialog function. A user asks the realistic anthropomorphic agent in a display some questions and some tasks, as if he/she usually asks his/her colleagues with a visual phone. It embodies a human-like face-to-face style communication environment, and therefore it will reduce the mental barrier for communication lying between a human and a computer. A prototype system of VSA is a development platform toward intelligent multimodal interface systems. Besides the texture-mapped realistic face, it equips a camera, a speech recognizer, a speech synthesizer, and some sensors; corresponding with eyes, ears, a mouth, and some sense organs, respectively. The system is also connected with World-Wide Web (WWW) / the Netscape navigator. As a result, it works just like a voice-controlled Netscape talking with a guide agent. A user navigates on the Internet by simple speech dialog with VSA besides an usual mouse interface in the Netscape. Both the voice-control operation through VSA and the mouse operation have the same priority. The user can choose the suitable operation method in any time in accordance with the various situations.
Figure 1: Visual Software Agent
(A user asks the realistic anthropomorphic agent in a display
some questions and some tasks just like using a visual phone.)
Today's pervasive interface style is direct manipulation. A mouse is a fairy
good device, but all of users can't manipulate it satisfactory. Some people
dislike a double clicking operation. In other words, current GUI interface
may be unusable for some people unfamiliar with computer operations and
physically handicapped persons. A good interface should be so simple and
so natural that a user doesn't give it second thought. Thus, software agents
assisting users personally become important[Laurel, 1990].
The word "software agent" generally means a software that performs intelligent
tasks autonomously like human agents. Many of software agents have no figure
and no face. Some people call this type of software as a "filter," not an
"agent."
Some research groups have developed software agent interface systems with
own faces and figures. The GUIDES system[Oren et al., 1990]presents some
"Guides" icons. Users select the favorite one of icons as a guide, and assume
characterization behind the iconic guide figures. The Maxims system[Lashkari
et al., 1994][Maes, 1994]selects E-mails based on the user's preferences,
and makes personalized suggestions to the user. It has a caricature face,
and it works as an indicator which communicates its internal state to users
via facial expressions.
The TOSBURG-II system[Takebayashi, 1994]has the agent for a communication,
animated hamburger-shop clerk. It equips powerful speech recognizer, and
users can order him with natural language. The DECface system[Waters and
Levergood, 1993]has a texture-mapped face with lip-synchronization. The
Talkman system[Takeuchi and Nagao, 1993]has a face based on Waters', and
makes multimodal human-computer conversation as a "social agent" [Nagao
and Takeuchi, 1994].
We have designed and implemented an anthropomorphic interface agent with
rocking realistic face and speech dialog function[Dohi and Ishizuka, 1993]as
a communication partner. We call this anthropomorphic agent as the Visual
Software Agent, or simply VSA. We connect our VSA with the World-Wide Web(WWW)[Berners-Lee
et al., 1994], as an Internet-based vast information database. VSA make
use of the Netscape navigator and the NCSA Mosaic as a hyper-text viewer.
Because of this connection, VSA can handle vast and various types information
stored in the Internet. A user can walk around the Internet world by talking
with VSA, besides a usual mouse interface on the Netscape.
Speech dialog is our main communication channel. The advantage of a voice-controlled interface is;
However, who wants to talk with a metal box in order to control a computer?
In the movie titled "2001: A Space Odyssey," captain Bowman talks and commands
by natural language with the computer with a lip-reader, HAL-9000, however
he never be aware in where HAL is.
Suppose that you are alone in your room and speak to yourself. You may
feel uneasy whenever you speak to without a communication partner. It may
be reluctant psychologically for a user to mutter to a simple metal box
of computer. An anthropomorphic agent with a realistic face will reduce
this mental barrier for communication lying between a human and a computer.
It embodies our common "face-to-face" style communication environment.
Figure 1 shows the example of the Visual Software Agent interface.
A user puts a headset on (or uses a microphone,) and asks VSA in a display
some questions and some tasks just like using a visual phone.
For the speech communication with a user, we have attached some commercial
speech products.
The speech recognizer is the "Phonetic Engine 200" (Speech Systems Inc.)
with Japanese speech-recognition function as an addition. It can recognize
speaker-independent and continuous speech.
Also, two speech synthesizers are attached to the workstation. These are
the "DECtalk" (Digital Equipment Corp.) for English and the "Shaberin-bo"
(NTT data) for Japanese.
VSA has a realistic face.
For generating the realistic facial image of the VSA, a real human photograph
is texture-mapped on a 3D wireframe model of a face.
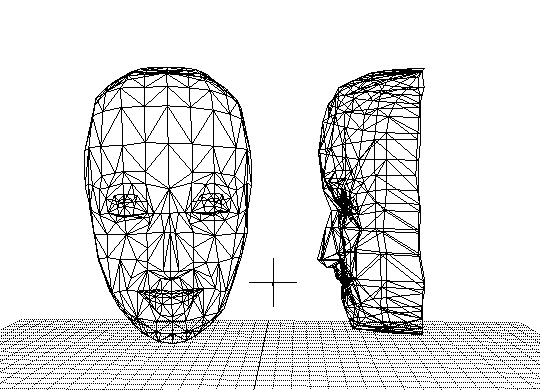
Figure 2: 3D wireframe face model
(It has only a front half, and a full face photograph is texture-mapped
on it.)
Figure 2 shows a 3D wireframe face model.
It has only a front half. It consists of about five hundred triangle surface
patches.
We use one full face photograph for texture-mapping. It is very easy to
match the real texture image with the 3D face model. We have developed a
VSA editor, then you have only to click three points on the displayed texture
image; that is, the right eye, the left eye, and the center of the mouth.
Arrangements are all. The system calculates the suitable position and the
scaling factor of the 3D face model. It can also move each vertex for the
precise matching, if necessary. Then it generates a texture-mapped realistic
face automatically.
The deformation of the wire frame model makes a change of facial expressions,
including winks (open/close eyes) and speaks (change mouth shapes synchronized
with a speech synthesizer.) The generated VSA face is also always rocking
naturally; these features give intimate feeling that can not be obtained
from static images.
The advantages of the texture-mapped 3D face compared with the animated
figure are;
Although the texture mapping technique requires high computational cost, recent computer graphics technology makes it possible to generate a vivid realistic facial image and change its facial expression in real-time.
For rocking realistic facial image synthesis in real-time, we have developed so far three modules. All modules have the same interface, so that we can choose one as we need.
The prototype of the original parallel transputers board (called "ViSA")
can generate a texture-mapped facial image 10-15 frames/sec on four transputer
chips.
In the motion J-PEG method, we make a facial image database. It has more
than 7,000 J-PEG compressed images with the combination of various face
directions and mouth shapes. Each original image is 640 480 pixels with
24 bits depth. The system arranges suitable compressed images picked up
from the image database according to the speech sentence and the movement
of the user, then it decompress the image sequence in real-time continuously
with the J-PEG decompression board. Using this technique, we can generate
the rocking realistic face in real-time even on a personal computer.
We have also implemented a real-time facial image synthesis module on the
OpenGL graphics library. A high-performance graphics board with a hardware
texture mapper can generate a rocking realistic face with various facial
expressions 30 frames/sec.
We connect our VSA with WWW as an Internet-based vast information database.
We have already implemented the VSA system connected with NCSA Mosaic[Dohi
and Ishizuka, 1996]. Recently, we have developed a new VSA system connected
with Netscape Navigator, instead of Mosaic. Both systems have the same interfaces
and functions, although the implementation method are different.
In August 1996, Netscape Communications Corporation and IBM announced the
development of a speech-enabled version of Netscape Navigator. It is based
on Netscape Navigator 2.02, and runs only on IBM OS/2 Warp 4.
In our VSA system, it is independent of the version of Netscape Navigator,
since we don't make any modification on Netscape. The latest VSA system
connects with Netscape Navigator 3.01, and runs on a UNIX workstation. It
can handle multi-language encodings including Japanese.
VSA makes use of Netscape Navigator as the part of the system, a hyper-media
viewer. Because of this connection, VSA can handle information described
in Hyper-Text Markup Language(HTML). In other words, VSA can make use of
vast information stored in the Internet. As a result, all hyper-media data
in the standardized HTML format can be used for VSA as well as WWW.
A user can walk around the Internet world using speech dialog, in addition
to a usual mouse interface on Netscape. Both the speech dialog interface
through VSA and the mouse interface have the same priority. All mouse controls
are any time available, independent of the use of voice control.
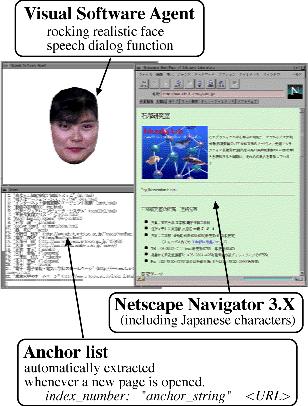
Figure 3: VSA system connected with WWW/Netscape
Figure 3 shows an example of the screen image of our VSA system connected
with Netscape Navigator. There are three windows. The right one is a Netscape
window. The upper left window shows VSA with a rocking realistic face. In
the lower left window, it displays the anchor list of the right Netscape
window. It is used for the voice-control of Netscape. Each entry of this
list is a triplet of the index number, the anchor string, and the URL.
< Index_number, Anchor_string, URL>
The anchor list is automatically extracted whenever a new page is opened.
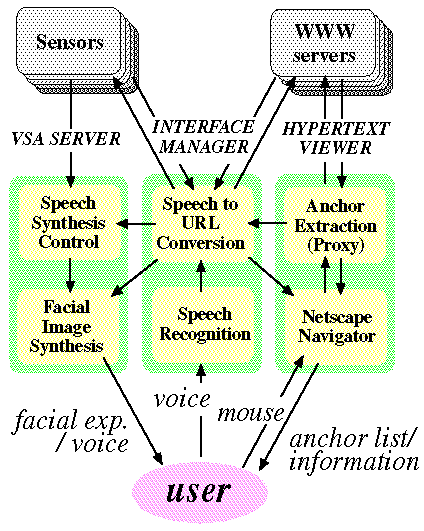
Figure 4: Configuration of VSA-Netscape Interface
(Six processes collaborate through TCP/IP and shared memories
on different workstations.)
Figure 4 illustrates the configuration of our VSA-Netscape interface.
There are three parts; the Interface manager, the VSA server, and the Hypertext
viewer. Each function is modularized and implemented as an independent process.
It is easy to add and replace new function processes. In the Netscape version's
basic implementation, each part consists of two processes. These six processes
can collaborate through TCP/IP and shared memories on different workstations.
The Interface manager converts a speech sentence into an associated URL
(Uniform Resource Locator), and controls Netscape and the VSA server. The
VSA server controls both the operations of speech synthesis and realistic
facial image synthesis with simple loose lip-synchronization.
In an earlier Mosaic version, we modified the source code(60K lines) of
Mosaic software to extract the anchor list. However in the Netscape version,
its source code is not available. Instead, we use a proxy technique to obtain
necessary data including the anchor list.
The interface manager allows multiple TCP/IP connections. There are various types of sensors, and can exchange sensor data with the Interface manager through TCP/IP; a moving camera tracking a user for eye contacts, a ultra sonic telemeter, an infrared sensor, a thermometer etc. Using this TCP/IP connections, it will also embody VSA-VSA communications.
Our current VSA system can answer to user's questions; i.e. date, time, room temperature, arrival of personal e-mails, and weather forecast etc. And also, it can recognize four types of speech commands for the Internet navigation.
The following examples illustrates the voice-control operation of Netscape.
User: Please contact with "the University of Tokyo" server.
VSA: Yes. Just a moment please.
(connect with the server, then present an anchor list)
User: Number 0, please.
(anchor_index 0: Japanese_version_)
VSA: Yes.
(open "Japanese" page, and present new anchor list)
User: Please show me c????s . . .
(the score value is under a threshold; it failed speech recognition)
VSA: Pardon?
User: Please show me "campus map"
VSA: Yes.
(open "campus map" page, and present new anchor list)
Example 1. A simple dialog example.
In this simple dialog example, a user speaks to VSA, and then VSA replies
with voice as well as changing pages in the Netscape window, if necessary.
The speech recognizer returns both a sentence recognized and its score
for decoding of the complete utterance. The score value is between 0 to
999 (best). If the score value is under a threshold, the VSA system discards
the returned sentence and prompts the user to speak the sentence again.
In a speech dialog system, the delay time of responses is important factor
for making a user comfortable.
When you want to know a weather forecast, you have only to talk with VSA,
"Please show me a weather forecast". Then, a relevant page is opened in
the Netscape window. However, it may not be necessarily comfortable for
you because we are sometimes kept waiting long time to get information because
of a traffic jam of the network. A user's request invokes downloading information
from the Internet, not displaying information.
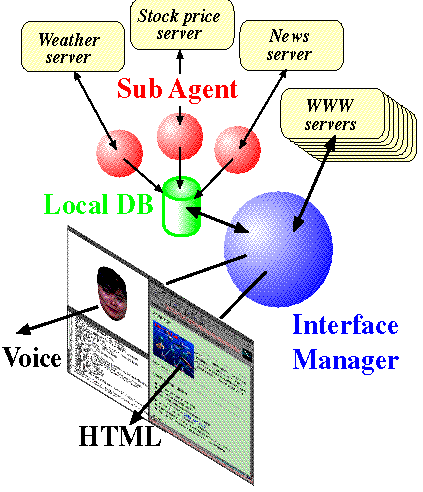
Figure 5: Sub agent
(sub agents autonomously gather information in advance and VSA responds
promptly to the user's question with voice and images, if necessary.)
In the VSA system, some sub agents autonomously gather information into
the local database, and VSA responds promptly to the user's question with
voice (and images, if necessary.) They are, for example, a weather forecast,
stock prices, and relevant news topics which include specific keywords.
The sub agent accesses periodically specific WWW servers, then picks necessary
information out from the WWW page, and updates the local database entry
automatically.
Many research groups have tried to develop a "general purpose" WWW page
analyzing system. However the current state of WWW pages are too chaotic
and too confused. They are a jumble of wheat and tares. Therefore we choose
a simple strategy. A user advises the system authoritative WWW pages in
advance. The WWW page is desirable that the contents is updated frequently,
but it keeps the page layout.
A user may get html files beforehand using prefetch and caching techniques.
In this case, however, the user need to search and pick up necessary information
from the page.
In the VSA system with sub agents, it tells the user by voice (and image)
only what he/she wants to know. In case of weather forecast, the weather
page in general includes information all over the country. When a user simply
asks the weather forecast, the VSA system judges the user wants to know
the weather forecast of the local district. Then VSA replies it promptly
with voice since the local database has the latest information of local
weather forecast. And, when asked about the weather forecast in another
place, VSA accesses the WWW server as usual, and opened its weather WWW
page.
There are some papers about the effect of the human face on a multimodal
interface [Walker et al., 1994][Takeuchi and Naito, 1995][Koda and Maes,
1996]. According to the observations about our guests' interests, we confirm
a rocking realistic face attracts strongly the user's attention to the display.
It is the interface style close to daily face-to-face communication with
speech dialog. For computer experts, however, it may be an annoying interface
because the performance of any current speech dialog systems is insufficient
yet for free talk. They can type a keyboard and click a mouse without any
difficulties, and are well aware that the speech input can't be always recognized
correctly. Then, our current target users are persons unfamiliar with computer
operations, physically handicapped persons, and all users in situations
that the mouse interface is not suitable; e.g., a speaker standing in front
of a wall-type room-wide screen on a stage and a person walking on a street.
In multimodal interface systems, some modalities should be complementary
each other. It is desirable for users to be able to choose the most suitable
interface modalities depend on the time, the place, and the occasion. We
don't intend to fully replace the mouse interface with the speech dialog
interface. If all anchor strings have unique names each other, the speech
dialog functions has an advantage, because the user need not to move a mouse
cursor onto another anchor. However, the speech operation can't necessarily
point out any location on a click-able map exactly.
We have developed a prototype of the Visual Software Agent system connected
with WWW and Netscape navigator. VSA offers a new multimodal interface with
a rocking realistic facial image and speech dialog function. It gives users
friendliness feeling, and it reduces the mental barrier for speech communication
lying between a human and a computer.
VSA delivers a user's speech request to WWW and Netscape. Thus, a user
can walk around the Internet by talking with the visual anthropomorphic
agent. It may broaden the usage style of WWW information and functions.
The interaction between the agent and a user becomes more smooth and natural,
and the agent can navigate the user in the vast Internet information space.
[Berners-Lee et al., 1994] T. Berners-Lee, R. Cailliau, A. Luotonen, H.F. Nielsen, and A. Secret.
"The World-Wide Web". Commun. ACM, 37(8):76-82, 1994.
[Dohi and Ishizuka, 1993] H. Dohi and M. Ishizuka. "Realtime Synthesis of a Realistic Anthropomorphous
Agent toward Advanced Human-Computer Interaction". In G. Salvendy and M.J.
Smith, editors, Human-Computer Interaction: Software and Hardware Interfaces, pages 152-157. Elsevier, 1993.
[Dohi and Ishizuka, 1996] H. Dohi and M. Ishizuka. "A Visual Software Agent: An Internet-Based Interface
Agent with Rocking Realistic Face and Speech Dialog Function". Working Notes of AAAI-96 Workshop on Internet-Based Information Systems, pages 35-40, Aug. 1996.
[Koda and Maes, 1996] T. Koda and P. Maes. "Agents with Faces: The Effects of Personification
of Agents". HCI'96, Aug. 1996.
[Lashkari et al., 1994] Y. Lashkari, M. Metral, and P. Maes. "Collaborative Interface Agents". Proc. 12th National Conference on Artificial Intelligence (AAAI-94), 1:444-449, Jul. 1994.
[Laurel, 1990]B. Laurel. "Interface Agents: Metaphors with Character". In B. Laurel, editor, The Art of Human-Computer Interface Design, pages 355-365. Addison-Wesley Publishing Company, Inc., 1990.
[Maes, 1994]P. Maes. "Agents that Reduce Work and Information Overload". Commun. ACM, 37(7):31-40, July 1994.
[Nagao and Takeuchi, 1994]K. Nagao and A. Takeuchi. "Speech Dialogue with Facial Displays: Multimodal
Human-Computer Conversation". 32nd Annual Meeting of the Association for Computational Linguistics (ACL-94), pages 102-109, 1994.
[Oren et al., 1990]T. Oren, G. Salomon, K. Kreitman, and A. Don. "Guides: Characterizing the
Interface". In B. Laurel, editor, The Art of Human-Computer Interface Design, pages 367-381. Addison-Wesley Publishing Company, Inc., 1990.
[Takebayashi, 1994]Y. Takebayashi. "Spontaneous Speech Dialogue System TOSBURG II -Towards
the User-Centered Multimodal Interface-". IEICE Trans. Information and Systems, J77-D-II(8):1417-1428, Aug. 1994.
[Takeuchi and Nagao, 1993]A. Takeuchi and K. Nagao. "Communicative Facial Displays as a New Conversational
Modality". ACM/IFIP INTERCHI'93 (INTERACT'93 and CHI'93), pages 187-193, 1993.
[Takeuchi and Naito, 1995] A. Takeuchi and T. Naito. "Situated Facial Displays: Towards Social Interaction". Proc. CHI'95 Human Factors in Computing Systems, pages 450-454, 1995.
[Walker et al., 1994]J.H. Walker, L. Sproull, and R. Subramani. "Using a Human Face in an Interface". Proc. CHI'94 Human Factors in Computing Systems, pages 85-91, 1994.
[Waters and Levergood, 1993] K. Waters and T.M. Levergood. "DECface: An Automatic Lip-Synchronization
Algorithm for Synthetic Faces". Technical Report CRL 93/4, Cambridge Research Center, Digital Equipment Corporation, Sep. 1993.