With the currently growing interest in the Semantic Web, metadata is coming to play an important role in the Web. As one emerging metadata standard for the Semantic Web, FOAF defines an RDF vocabulary for expressing metadata about people and the relation among them. This paper proposes a novel keyword extraction method to extract FOAF metadata from the Web. The proposed method is based on cooccurrence information of words. Our method extracts relevant keywords depending on the context of a person. Our experimental results show that extracted keywords are useful for FOAF metadata creation. We also discuss the application of this keyword extraction method.
FOAF, metadata, keyword extraction, word cooccurrence
With the current Web trends such as the Semantic Web and Social Networking, ``Friend of a Friend'', FOAF [1], project defines an RDF vocabulary for expressing metadata about people, the links between them, and the things they create and do. FOAF provides a way to create machine-readable documents on the Web, and to process them easily through merging and aggregating them. In relation to the Semantic Web, FOAF facilitates the creation of the Semantic Web equivalent of the archetypal personal homepage. With respect to ``Social Networking'', FOAF is considered as a Social Networking metadata standard that can be applied to myriad services.
A major hurdle of the Semantic Web is the creation of metadata. Although the RDF provides a rich foundation to describe metadata, it remains difficult for users to create metadata. To overcome this limitation, one needs methods that facilitate and accelerate metadata creation. Currently, FOAF documents are created by a user describing his or her information (the user can also describe another person's information) using the FOAF vocabulary. Although there are supporting tools to create FOAF documents, such as Foaf-a-Matic[2], this tool facilitates only basic descriptions.
One way to solve the problem of metadata creation is to extract metadata from the Web. There are billions documents in the Web. However, most of the documents have no attached metadata and are not machine-readable, even though these documents have the potential to provide some sort of metadata. Considering the personal information that the FOAF vocabulary expresses, we notice that a lot of information is contained in the Web pages. For example, imagine a researcher:that researcher's information can be in an affiliation page, a conference page, an online paper, or even in a blog. In fact, we can expect that these pages contain a lot of FOAF metadata even including information that we would not expect to find.
Information Extraction (IE)[3] based on machine learning and natural language processing technology is currently used to extract metadata from documents. For extraction of personal information, most IE researches have specifically addressed information such as affiliation, email address, and URLs[4]. A further challenge is to extract more varied kinds of personal information. The personal information is different depending on a person's context. When extracting personal information, it is important to capture different personal aspects in different contexts.
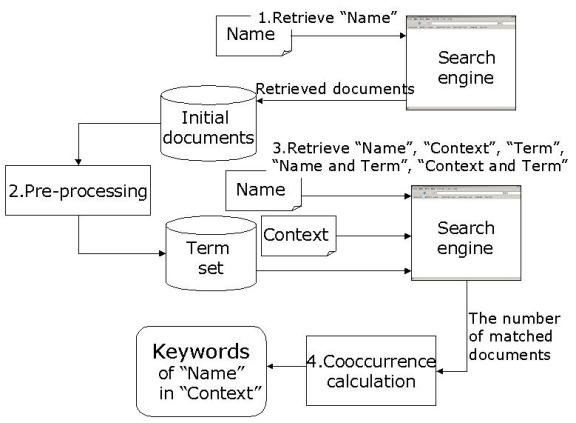
One of our research goals is to extract metadata of people in their various contexts. The extracted metadata would be expressed in the FOAF vocabulary and its extension. As a preliminary report to achieve this goal, we propose a novel keyword extraction method to extract personal information from the Web. As an term set for a user's keyword, we use terms extracted from Web pages that include a user's name in the text. Subsequently the keyword of a user is extracted based on the degree of cooccurrence between the name and terms. The degree of cooccurrence is calculated using the search engine result. To extract the relevant keyword for a user, the user context is also considered in the keyword extraction.
Using the proposed method, we extracted the keywords of committee members of this workshop. Our hypothesis is that some FOAF metadata of a person is included in the extracted keywords. We analyze the extracted keywords to verify this hypothesis and explore the possibility of FOAF metadata extraction from the Web. In particular, we analyze the following points.
In accordance with this analysis, we also discuss how the proposed keyword extraction method contributes to actual creation of a FOAF file and the social network. Furthermore, we refer to the privacy issue of extracting personal information from the Web, and its relation to information publicity of FOAF.
The remainder of this paper is organized as follows: section 2 describes the proposed keyword extraction method using an actual example. In section 3, we show the extracted keywords and analyze them. Section 4 contains discussion of issues and future work. Section 5 contains related works. Finally, we conclude this paper in section 6.
As an experimental attempt, we extracted the keywords of program committee members of this Workshop(There are 25 Program Committee members including four chairs). First, we need to acquire Web pages that contain information of respective committee members and their mutual relationships. A simple way of acquiring those Web pages is to use a search engine. It is reasonable to use a search engine because it can search many Web pages in less than a few seconds. It also tracks the temporal variance of the Web. In this experiment, we used Google[5], which currently addresses data from 4 billion Web pages.
We first put each person's full name to a search engine (Names are quoted as double quotation such as ``Dan Brickley'') and retrieve documents related to each person. From the search result, we used the top 10 documents per a person as the initial documents that might contain personal keywords.
The search result documents include not only html files but also other file types such as .pdf, .doc, .xls, .ppt, and other file types. In this experiment, we used only html files. Furthermore, we did not use metadata indicators in an html file such as META tags and RDF. In the future, we are planning to use other file types along with html files that already have attached metadata.
The html files, at to a maximum of 10 files per person, are acquired from the initial documents of each person. They are pre-processed with html tag deletion and part-of-speech tagging (POS). Then the term set for keyword extraction is extracted from pre-processed html files using the term extraction tool, Termex [6]. Termex extracts terms from POS data based on statistical information of conjunctions between parts of speech. Termex can also extract nominal phrases that include more than two nouns such as ``FOAF explorer''. After the whole procedure of extracting the term set, we extracted about 1000 terms per person on the average. The relevant keyword of each person is chosen from these terms.
In the followings, we consider problems in extracting the term set.
It is arguable how may documents of a search result are to be used. As we explain later, we need another use of a search engine to get cooccurence information that is necessary for calculation of keyword relevancy. The more we use the initial documents and have initial terms, the greater the number of queries must be posted to a search engine later. For that reason, we used the top 10 documents of search results to reduce the load of using a search engine. However, we must examine how many documents in a search result are to be used to extract a good keyword.
In obtaining documents for a keyword extraction, we used only the documents of the search results. However, we might obtain other useful documents for keyword extraction by tracking further links from initial documents. For example, if one's personal page is among the initial documents, we can obtain more related pages about that person by tracking links in a personal page. On the other hand, link-tracking often leads us to irrelevant pages and a large number of Web pages. Hence, we should carefully consider the depth of links to track in acquiring further initial documents for keyword extraction.
We use higher-ranked documents of a search result. For that reason, our keyword extraction method depends partly on the scoring algorithm of a search engine. However, if we know which Web page contains important information for keyword extraction, we can choose only those relevant Web pages without merely using all Web pages in a search result. In relation to this, in sect.3.2 we analyze which Web page contains what kind of personal metadata.
One problem of retrieving a person's name in a search engine is the case of two or more people having the same full name. For example, in this experiment, the top 10 pages of the search result for the name ``Tom Baker'' are taken up by British actor pages. One way to alleviate this same-name problem is to add a person's affiliation to the query. In this ``Tom Baker'' case, with the query ``Tom Baker and GMD'' we can exclude the British actor's pages from the search result. However, this degrades the coverage of search results. In particular, this makes the search focus more on one's activity in relation to the affiliation. It also excludes other contexts. As we explain in the next subsection, our keyword extraction method is to capture personal information in different contexts. Therefore, it will be necessary to solve the same-name problem without losing various contexts of people. In this experiment, we adopt a query with the affiliation only to users that their search results are taken up by another person of the same name.
Figure.1 shows steps of the proposed keyword extraction.
Given the term set, we can expect that there might be many useful terms for personal information in the set. On the other there is expected to be irrelevant terms. This subsection explains the scoring method that gives relevance as a personal keyword to the term.
The simplest approach to measure term relevance as a person's keyword is to use cooccurrence. In this paper, we define cooccurrence of two terms as term appearance in the same Web page. If two terms cooccur in many pages, we can say that those two have a strong relation and one term is relevant for another term. This cooccurrence information is acquired by the number of retrieved results of a search engine. For example, assume we are to measure the relevance of name ``N''and term ``w''. Here, ``w'' is the term in the term set W extracted from the initial documents of the person named ``N'' . We first put a query, ``N and w'', to a search engine and obtain the number of retrieved documents. This number of retrieved documents denoted by |N and w| is the cooccurrence between ``N'' and ``w'' . We continuously apply a query, ``N'' and ``w'', and get the number of matched documents for each, |N| and |w|. Then, the relevance between the name ``N'' and the term ``w'', denoted by r(N,w), is approximated by the following Jaccard coefficient.
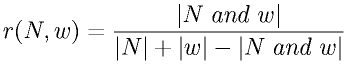
This Jaccard coefficient captures the degree of cooccurrence of two terms by their mutual degree of overlap.
As described in a previous subsection, the term set of a person is extracted from various Web pages as a search result. Although such pages contain a person's name in the text, some pages may contain the information of a different context of a person. For example, imagine that one person, named ``Tom'', is both a researcher and a artist, we can expect that his name may appear not only in academic-related pages, but also in other pages related to his art activities. Even among his academic-related pages, there might be different pages depending on his acquaintances, affiliations, and projects. In this way, different Web pages reflect different contexts of a person. Here, we introduce the notion of a context to extract the keyword that captures the context of a person.
To extract the keyword in relation to a certain context, we must estimate the relevance between the term and the context. If we replace the name ``N'' with the context ``C'' in the relevance, r(N,w), we can obtain the relevance between context ``C'' and term ``w'', r(C,w), in the same manner. Then, the relevance of person ``N'' and term ``w'' in the context ``C'', denoted by score(N,C,w), is calculated as the following.
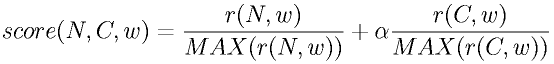
Therein, alpha denotes the relevance between the person and the context. For example, we can use r(N,C) as alpha. MAX(r(X,Y)) is the maximum value of the Jaccard coefficient in the term set W. We define the threshold for r(N,w) to exclude terms that are not relevant for a person, but that have strong relation to the context. The term ``w'' with the higher score(N,C,w) is considered to be a more relevant keyword for person ``N'' in context ``C''.
Regarding the ``Tom'' example, if we set ``art'' as the context, we can get keywords related to his art activities. Alternatively, if we include his research project name as the context, the keywords related to his project would be acquired. Here, we infer that information related to the context is on the Web. However, some information is apparently not available. We must consider the availability of the contextual information from the Web.
If we consider the relation between two persons in terms of their contexts, one person can be regarded as a part of the context of another person. Hence, we can apply the previous formula to keyword extraction of the relations among persons as follows:
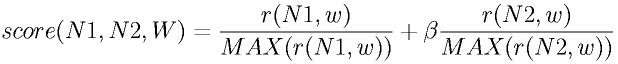
Therein, ``N1'' and ``N2'' denote each person's names in the relation. beta is the parameter of relevance between persons, such as r(N1,N2). This formula shows the relevance of person ``N1'''s term ``w'' in relation to person ``N2''.
There are many contexts of a person. Therefore, the relations among persons also have a variety of contexts. For example, the relation of two persons in the academic field might be coauthors, have the same affiliation, the same project; they may even be friends. The relevance of person ``N1'''s term ``w'' in relation to person ``N2'' in the context ``C'', score(N1,N2,C,w), is given as follows:
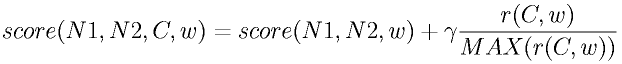
Therein, gamma is the parameter of relevance between the persons and the context, such as r(N1 and N2,C).
As an example of extracted keywords, Tables 1 and 2 shows higher-ranked extracted keywords of ``Dan Brickley'' and ``Liddy Miller'', respectively. Each column in the table shows higher-ranked keywords based on Term Frequency Inverse Document Frequency(tfidf) method, cooccurrence-based method without the context, and cooccurrence-based method with the context, respectively, from the left column. tfidf is a method widely used by many keyword extraction systems to score individual words within text documents in order to select concepts that accurately represent the content of the document. tfidf score of a word can be calculated by looking at the number of times the word appears in a document and multiplying that number by the log of the total number of documents(corpora) divide by the number of documents that the word resides in. As corpora, we used the initial documents set(235 html files).
In tfidf-based keywords, we can find keywords that are related to the person such as ``RDF'' and ``Semantic''. Nevertheless there are many irrelevant words including general words. Because tfidf is based on the frequency of word appearances in a text, it is difficult for a word to become higher-ranked in terms of relevance with another word. On the other hand, in cooccurrence-based keywords, general words are excluded and relevant words of each person appear in the rank list.
As explained in the previous section, the context is considered to be the keyword extraction. In this experiment, we used ``FOAF'' as the context. With this context, keywords are chosen in relation to FOAF. In the column of ``Cooccurrence with the context'', we can find that context-related keywords (in bold type) come to appear in the rank list. The order of higher-ranked keywords also changes in relation to the context.
|
|
|
|
The column at the right side shows a property label for each keyword in ``Cooccurrence with the context''. We have defined eight property labels. Because we consider the relation between extracted keywords and FOAF metadata, each property is chosen by considering a rough correspondence to examples of ``foaf:Person domain'' shown in parentheses. (There is no FOAF property for Event and Position, but these properties can be useful personal metadata.)
By examining each keyword with its property label, we find various persons' metadata such as personal names, organization names, and project names among the higher-ranked keywords. To analyze what kind of property is included in keywords, we annotated a property label to higher-ranked keywords of each person. Thereby we acquired 1392 labeled keywords in total (about 55 keywords per person on average). Table.3 shows the distribution of property labeled to higher-ranked keywords. Nearly half of higher-ranked keywords are occupied with technical terms. Notwithstanding it is noteworthy that other properties such as personal names, organizations, and projects also appear to a certain degree. In particular, as shown on the right side column, the properties for each person are distributed in a balanced manner. This distribution means that if we extract about 55 higher-ranked keywords of one person, in average we can obtain about 20 names of his acquaintance, 2 or 3 related organizations, and 1 or 2 projects. These numbers nearly match our daily activity and show the possibility of using keywords for FOAF metadata extraction. In this analysis, we took many keywords together as ``technical terms''. If we classify each keyword more precisely, we can discover other FOAF metadata in keywords.
| Property | Number | Per person |
| Technical term Name Organization URL Project Event Community Position |
695(49.9%) 476(34.1%) 71(5.1%) 65(4.6%) 35(2.5%) 31(2.2%) 10(0.7%) 9(0.6%) |
27.8 19.04 2.84 2.6 1.4 1.24 0.4 0.36 |
| Total | 1392 |
To further explore the possibility of FOAF metadata extraction from the Web, we analyzed which Web pages include a higher-ranked keyword. First, we classified all 250 web pages (10 per person) that were used to extract the initial term set. Thereby, we produced the 17 categories shown in Table.4. ``Personal page'' includes personal Web pages of the organization or one's own domain. ``Other page'' includes uncategorized pages and non-html pages such as .pdf and .ppt files. ``Event page'' includes Conference, Workshop, and Meeting pages. ML log is the email exchanged in a mailing list. We separated a person's own blog from another person's Weblog because a person's name is often referred not only from one's own blog, but also from another person's blog. DBLP [7] is the online bibliography of Computer Science papers.
| Web page | Number |
| Personal page Other page Article Other Weblog Event ML log Own Weblog Online paper DBLP Organization Book Social netwok Online community Project RDF Topic map Other person's page |
58(23.3%) 28(11.2%) 25(10.0%) 22(8.8%) 14(5.6%) 14(5.6%) 13(5.2%) 13(5.2%) 12(4.8%) 10(4.0%) 10(4.0%) 9(3.6%) 6(2.4%) 5(2.0%) 5(2.0%) 4(1.6%) 2(0.8%) |
| Total | 250 |
As seen in the table, ``Personal page'' is the most dominant type of Web page. Because a person's name was used as a query, it is natural that we obtain a personal page at the top of a search result. An interesting result is that many blog pages, in particular another person's blog, are included in search results. This means that we can find one person's information not only in a personal blog, but also in another person's blog. Blogs offer the potential to be an information resource for personal metadata.
Table.5 shows which category of Web page a higher-ranked keyword belongs in (a keyword may appear in more than one category). Specifically examining each column, we find which kind of Web page each property is included in. Moving the focus to a row in the table, we can discover what kind of property each Web page category includes. Technical terms are included most in blogs. However, it is fairly safe to focus on ``Personal page'' to obtain more specific technical terms of a person. Although name entities can be acquired most from ``Personal page'', DBLP is also good information resource to extract a name entity. DBLP contains coauthor information of a paper. Therefore, the extracted name is related to one's acquaintance in a research activity. On the other hand, blogs are expected to contain information of more personal relations such as friends. In an organization property, the ML log provides the most information. Although this is an interesting result, we believe that ``Personal page'' gives more accurate information about the organization that is related to each person.
Overall, ``Personal page'' is a good information source for personal metadata such as names, organizations, and projects. DBLP provides the metadata that are related to personal research activities such as coauthors, projects, and events including conferences and workshops. In addition to these Web pages, blogs will be interesting information resource for personal metadata. One reason is that they contain more personal information. Another reason is that they track the change of information through frequent page updates.
| Web page | Technical Term | Name | Organization | URL | Project | Event | Position |
| Personal Page Weblog Other page Article Event ML log Online paper DBLP Organization Book Social network Online community Project RDF Topic map |
178(19.0%) 307(32.7%) 60(6.4%) 126(13.4%) 29(3.0%) 51(5.4%) 54(5.7%) 56(5.9%) 6(0.6%) 22(2.3%) 9(0.9%) 6(0.6%) 21(2.2%) 4(0.4%) 8(0.8%) |
181(22.4%) 81(10.0%) 70(8.6%) 61(7.5%) 19(2.3%) 55(6.8%) 33(4.0%) 148(18.3%) 70(8.6%) 23(2.8%) 26(3.2%) 3(0.3%) 8(1.0%) 6(0.7%) 24(2.9%) |
19(20.0%) 16(16.8%) 7(7.3%) 8(8.4%) 6(6.3%) 23(24.2%) 5(5.2%) 2(2.1%) 5(5.2%) 2(2.1%) 0 0 0 1(1.0%) 1(1.0%) |
9(11.0%) 17(20.7%) 13(15.8%) 13(15.8%) 1(1.2%) 18(21.9%) 1(1.2%) 0 0 0 6(7.3%) 0 2(2.4%) 1(1.2%) 1(1.2%) |
20(35.0%) 8(14.0%) 1(1.7%) 4(7.0%) 4(7.0%) 1(1.7%) 6(10.5%) 10(17.5%) 1(1.7%) 2(3.5%) 0 0 0 0 0 |
7(16.6%) 5(11.9%) 4(9.5%) 1(2.3%) 0 4(9.5%) 1(2.3%) 19(45.2%) 0 1(2.3%) 0 0 0 0 0 |
5(29.4%) 4(23.5%) 1(5.8%) 4(23.5%) 1(5.8%) 0 0 0 0 0 0 0 0 0 2(11.7%) |
| Total | 937 | 808 | 95 | 82 | 57 | 42 | 17 |
As our analysis showed, our personal keyword extraction method offers strong potential for FOAF metadata extraction from the Web. For example, Using keywords of ``Dan Brickley'' in Table.1, we can create the following FOAF template file.
<foaf:Person> <foaf:mbox rdf:resource=""/> <foaf:name>Dan Brickley </foaf:name> <foaf:interest rdfs:label="FOAF" rdf:resource=""/> <foaf:interest rdfs:label="Semantic Web" rdf:resource=""/> <foaf:currentProject rdfs:label ="SWAD" rdf:resource=""/> <foaf:workplaceHomepage rdfs:label="ILRT" rdf:resource=""/> <foaf:knows> <foaf:Person> <foaf:mbox rdf:resource=""/> <foaf:name>Libby Miller</foaf:name> ...... <rdfs:seeAlso rdf:resource="page contains many keywords">
A keyword can be used an indicator of a ``seeAlso'' resource. If a Web page contains many higher-ranked keywords, that Web page is considered to be a relevant page of a person. Therefore we can refer to the page by ``rdf:seeAlso'' from the person's FOAF files. Alternatively, if we know the FOAF property corresponding to the keyword in the Web page, we can use the page as the ``rdf:resource'' of the property.
One problem is that we are not sure that these extracted metadata are true. Although two names, Dan and Libby, cooccur in many Web pages, they might not know each other. Therefore, someone should evaluate the propriety of a keyword as actual metadata. One approach to solve this problem would be an interactive system of FOAF file creation. Reusing and modifying a keyword as a candidate of FOAF metadata, a user can easily create his or her own or another person's FOAF.
Another problem of using keywords as FOAF metadata is to decide a certain keyword property. In our experiment, the property label was given manually to each keyword. However, it is not efficient to put a property to numerous extracted keywords. One approach to automatically decide the property of a keyword is to use the machine learning technique that is often used in the entity extraction research.
This paper presents discussion of the importance of a person's context in keyword extraction. The context often defines the properties. Currently, there is no FOAF vocabulary to define a context. One way to introduce the notion of a person's context to FOAF is to prepare schema that correspond to respective contexts.
People may have a common friend, share a common interest, and work at the same organization or project. These things are considered to be metadata that explain the relations among people. As explained in sect.2.2, a keyword can be extracted not only for a person, but also the relation between persons. Then, the extracted keyword may include metadata of the people relation. Table.6 shows keywords of the relation between ``Dan Brickley'' and ``Libby Miller''. Bold typed keywords in the table show common keywords for two persons. For example, we can guess the relation between them as follows: They belong in the ``ILRT'' and are involved in the ``SWAD'' project and have a common acquaintance named ``Jan Grant''.
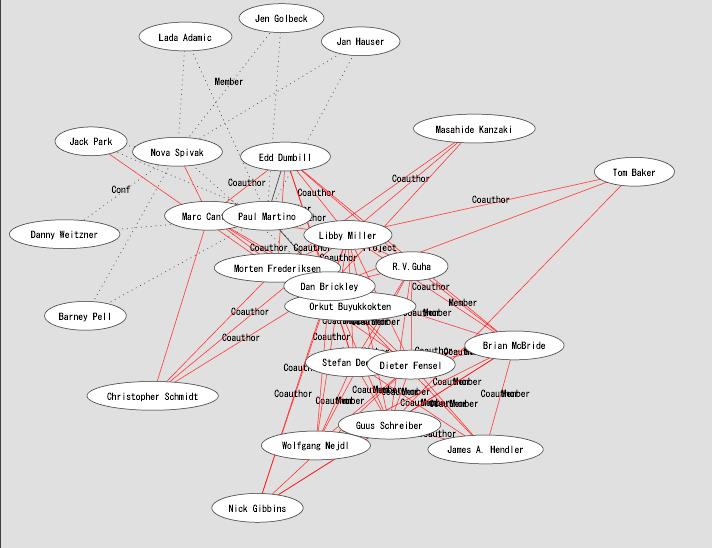
We are currently developing a novel method to extract a social network from the Web [8]. Figure.2 shows the social network of FOAF Workshop Program Committees. Along with keywords of a person, the keywords of the relation among persons yields semantics to the social network. By combining the social network with the keywords, we can comprehend information about nodes and edges on the network. More importantly it is possible to provide many services such as person recommendations or finding a community in the network.
| Dan Brickley -> Libby Miller | Libby Miller -> Dan Brickley |
| Dan Brickley Libby Miller DanBri danbri FOAF Semantic Web Dave Beckett RDFWeb ILRT SWAD Dan Connolly Foaf file Jan Grant xmlns.com/foaf RDF Interest Group Eric Miller RDF Vocabulary Foaf Explorer rdfweb.org/people Aaron Swartz |
Libby Miller Daniel Brickley FOAF RDFweb foaf file RDF schema ILRT SWAD rdfig Jan Grant FOAFs Semantic Web RDF SemWeb local news headlines Stefan Decker RDF query language Max Froumentin Foaf wiki senior technical researcher |
One problem included in FOAF is privacy of information. Because some information in one's FOAF documents may include private information, FOAF documents must sometimes be treated out of consideration to privacy issues. On the other hand, metadata extracted from the Web have been given some publicity because they have already been in the public domain. Therefore, we can use metadata that are extracted from the Web without concern about a privacy control problem. A person sometimes does not know that his or her information is extracted from the Web only by name. Therefore we should take care not to intrude on a user's privacy even in information extracted from the Web. We must clarify the use of the information only for useful services for a user.
In addition to privacy problems, another potential problem is copyright. Some Web pages prevent the utilization of their contents for revision or manipulation, especially for commercial objectives. We must pay attention to this problem when we use keyword extraction as a public service.
Aiming at extracting personal information as keywords, our method is regarded as one of Information Extraction(IE) methods. Up to now, many IE methods rely on predefined templates and linguistic rules or machine learning techniques to identify certain entities in text documents[9]. Furthermore, they usually define properties, domains, or ontology beforehand. However, because we try to extract various information from different Web pages, we don't use predefined restrictions in the extraction.
Some previous IE researches have addressed the extraction of personal information. In[10], they proposes the method to extract a artist information, such as name and date of birth, from documents and automatically generate his or her biography. They attempt to identify entity relationships, metadata triples (subject-relation-object), using ontology-relation declarations and lexical information. However, Web pages often include free texts and unstructured data. Thereby, capturing entity relationships becomes infeasible because of lacking regular sentences. Rather than focusing on the entity relationship, we find the entity in the Web pages based on the relevance in relation to a person.
In[11], they address the extraction of personal information such as name, project, publication in a specific department using unsupervised information extraction. It learns to automatically annotate domain-specific information from large repositories such as the Web with minimum user intervention. Although they extract various personal information, they don't consider the relevance of extracted information.
Although the aim is not extracting personal information, in[12], they proposes the method to extract a domain terminology from available documents such as the Web pages. The method is based on two measures, Domain Relevance and Domain Consensus, that give the specificity of a terminological candidate. This method is similar to our one in terms of that terminology are extracted based on the scoring measure. However, their measure is based not on the cooccurence but on the frequency. Furthermore, they focus on the domain-specific terms rather than personal information and the method is domain dependent. In our method, we can capture the various aspects of personal information even from different domain resources using the notion of a context.
The Web holds much personal information that can be used as FOAF metadata. This paper proposes a novel keyword extraction method to extract personal information from the Web. Our result showed the important possibility of using extracted keywords as FOAF metadata. Importantly our method can capture the personal information in a different context. This allows us to obtain various person-related metadata.
Because the Web is such a large information resource, its information runs the gamut from useful to trivial. It presents the limitation that it must be publicly available on the Web. To date, ordinary people have rarely expose their personal information on the Web. For further improvement of the proposed method, we must analyze ``what'' information of ``who'' in the Web, and its reliability. In this regard, Weblog, Social network, and CMS sites are noteworthy subjects for the future.
Granted as a scholarship student of Ecole Polytechnique Federal Lausanne (EPFL) of Switzerland, the first author is currently working in the Artificial Intelligent Laboratory (LIA) in EPFL. We thank LIA members for their useful comments on this paper.