Abstract
Multimodal anthropomorphic (or lifelike) agent interfaces are emerging as a promising new style of human interface beyond current GUI (graphical user interface). In this paper, we present an outline of our multimodal anthropomorphic agent system called VSA (visual software agent), which has a realistic moving face and functions of eye, ear, mouth and dialogues. A notable feature of VSA is a connection with a WWW browser; thereby, VSA allows us to access the vast information sources in the WWW through its friendly multimodal interface close to daily face-to-face communication. As an extension of VSA, we also introduce our VPA (visual page agent), aiming at a tool for making new multimodal (semi-interactive) Web contents.
1. Introduction
With the spread of computer use in the society, various new styles of human interfaces are appearing. One of such promising styles will be a multimodal anthropomorphic (or lifelike) agent interface. It aims to realize a natural and friendly interface close to daily face-to-face communication. Supported by increasing computer power, a new scene of human-computer interaction is going to open.
An idea or a thought in the human brain has a wide spectrum spanning from intellectual aspect to emotional one. Hence, a single media or a single modality, such as text, image, voice, etc., is not enough to convey the idea properly. It is revealed that non-verbal factors, such as facial expression, gesture, gaze, speech intonation, etc., are playing a major role in our daily communication. We mostly feel comfortable with face-to-face communication where multimodal channels are available.
The currently dominating style of the human-computer interface is GUI (graphical user interface), which is based on the notion of direct manipulation and allows the style of ?ee & Point· Beyond GUI, PUI (perceptual user interface) or Agent Interface attracts the interests of researchers. It seems that PUI emphasizes the multimodality and the Agent Interface emphasizes indirect manipulation. It can be said that Agent plus Visual life-likeness allows a ?sk & Tell·style perceptual interface. (See Fig. 1.)
As shown in Fig. 2, there are several communication modalities including hapticable and olfactable modalities. Major two modalities are, however, visible and audible ones.
In this paper, we present our multimodal anthropomorphic agent system called VSA (visual software agent), which has a realistic moving face and functions of eye, ear, mouth and dialogues. A notable feature of VSA is a connection with a WWW browser. Thereby, VSA allows us to access the vast information sources in the Internet/WWW through its friendly multimodal interface close to face-to-face communication.
|
----------------------------------------------------- *Keyboard "Remember & Type"*GUI -- direct manipulation *Agent Interface ----------------------------------------------------- Fig. 1 GUI v.s. PUI/Agent Interface. |
|
----------------------------------------------------- *Visible- Graphics (including Texts) {2D, 3D}, - Gesture, Eye Line <-- non-verbal - Facial Expression <-- non-verbal *Audible - Voice *Hapticable *Olfactable ----------------------------------------------------- Fig. 2 Taxonomy of multimodalities. | |||||||||||
As an extension of VSA, we also introduce our VPA (visual page agent) system. VPA aims at not only providing a new interface to the WWW space, but also providing a tool for making new multimodal (semi-interactive) Web contents. Thus VPA data are embedded in an HTML page and transferred through the network.
2. Overview of VSA
In 1980s, Aran Kay [Kay 84] and others advocated agent interface as a necessary evolution of human interfaces. In 1988, Apple Computer, Inc. showed the concept video of?nowledge Navigator?or indicating a future human interface style. A digital assistant with a lifelike character was there. It was, however, only a video demonstration, and not produced in reality. Brenda Laurel wrote an article about interface agents with characters in [Laurel 90].
In 1990, we started our research to use computer-generated human face for a friendly multimodal human interface [Ishizuka 91]. We have named our system VSA (visual software agent), which early version is shown in Figure 3. Unlike other lifelike agent systems, we have been using a realistic texture-mapped facial image. (Figure 4 shows our 3D facial model.)
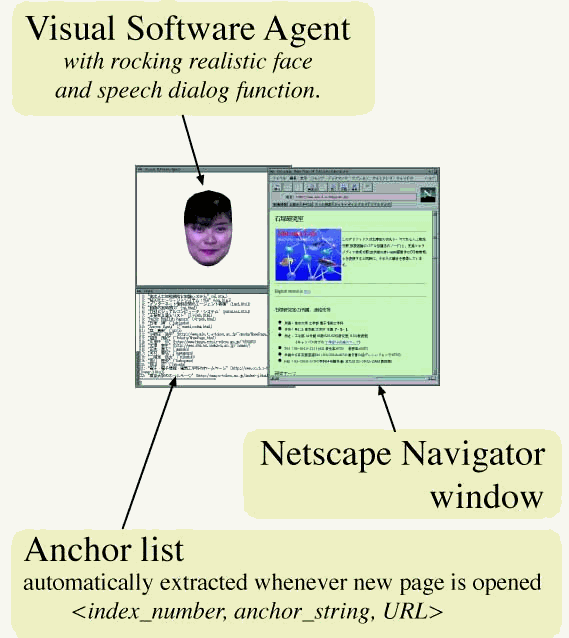
Before 1994, it was not an easy task to construct attractive and meaningful information contents that were provided through VSA. Since 1995, our VSA has been successfully connected with Web browsers [Dohi 96a, 96b, 96d, 97a, 97b], firstly with Mosaic, then with Netscape. Thus it can now serve as a new multimodal interface surface to the WWW information space where heterogeneous but a vast amount of information exists. Figure 5 depicts a VSA display connected with the Netscape Web browser.

Fig. 3 VSA (Visual Software Agent) -- Early stage.

Fig. 4 Realistic texture-mapped moving face.
Recently, we are developing VPA (visual page agent), an evolved version of VSA, which aims at a functionality or tool for making Web-based multimodal contents, not only a multimodal interface for the WWW.
3. Component Technologies
To realize the multimodal anthropomorphic-agent interface, many component technologies have to be integrated into the system. They are functions for facial image synthesis, eye (vision), ear (speech recognition), mouth (speech synthesis), coordination of modalities, dialogue, emotion, personality, etc. Also, for proper evaluation, a connection with an attractive information source becomes necessary. In the following, we will introduce some of the technologies we have developed for our VSA system, though not all of them are incorporated into the current system.
3.1 Transputer-based Parallel Computing System for Realtime Moving Image Recognition and Synthesis
When we started the VSA research around 1990, the power of general-purpose computers was not enough to perform realtime moving image recognition and synthesis. There were special processors dedicated to particular image processing tasks. However, we wanted a parallel computing system with wide-range programming flexibility. Thus, we decided to built a scalable parallel computing system using transputers with which a parallel programming language Occam was accompanied. In order to achieve the realtime transfer of moving image data, we designed and built a parallel (32-bit width) video-rate data bus for the parallel computing system [Wongwarawipat 90, 91]. Figures 6 and 7 show the configuration and the picture, respectively, of this parallel computing system called TN-VIT. It had 48 transputers (T-805), and worked nicely both for the realtime recognition of moving human images and for the realtime synthesis of texture-mapped moving human faces [Hasegawa 91, 92a, 92b, 95].

Fig. 6 TN-VIT (Transputer Network with Visual Interface).
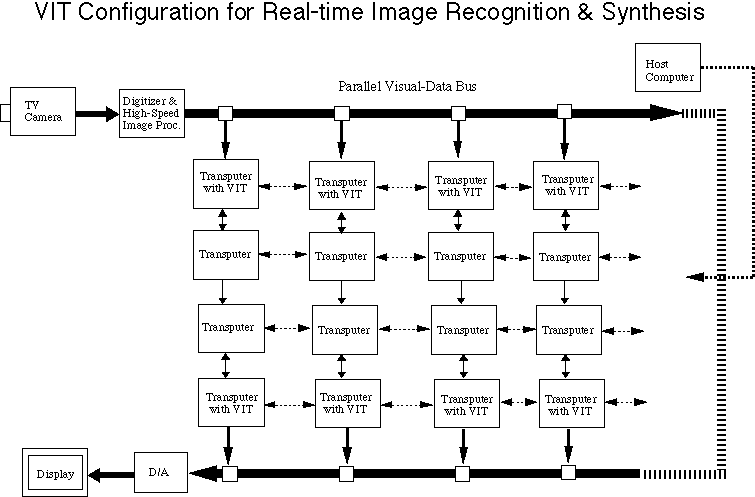
Fig. 7 Configuration of TN-VIT
While the transputer together with its parallel programming language Occam provided a convenient tool for parallel computing, it could not succeed in the market. Meanwhile, with the support of some attached processors, general-purpose graphics workstations became capable of performing the realtime synthesis of texture-mapped moving images. Our VSA is now running on such a graphics workstation, and is expected to run on personal computers soon.
3.2 Speech Recognition/Synthesis
Speech or voice is an indispensable modality for the anthropomorphic agent. For the speech recognition and synthesis for our VSA, we are using the following commercial products
- Phonetic Engine-2000 (Japanese ver.) etc. for speech recognition,
- DECtalk for English speech synthesis, and
Shaberin-bo (NTT Data), etc. for Japanese speech synthesis.
To catch the meaning of users' utterance which often bears ambiguity, a word spotting technique is employed. A dialogue management module including a simple user model has been also developed [Hiramoto 94] as shown in Fig. 8.
In addition to speech synthesis, a mechanism of lip synchronization with speech output is required for the multimodal anthropomorphic agent. This is achieved in Japanese case by extracting 5 vowels from a speech text and then generating a pseudo-synchronized sequence of lip patterns. In English case, it is not so easy because the pronunciation does not exactly correspond to the text. Thus we have combined a pronunciation dictionary in order to translate the text into lip patterns. (In recent commercial products, however, a much simpler technique is used for pseudo lip synchronization in English case.)
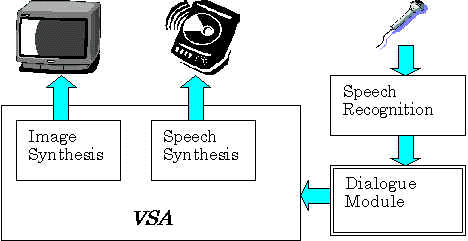
Fig. 8 Speech recognition / synthesis.
3.3 Vision System
Vision functions are required for friendly human-computer interactions. We have developed several vision functions for the VSA system [Hasegawa 93, 94a, 94b][Dohi 96c][Huang 95, 96, 97]. Here, we introduce one of them.
Figures 9 shows a vision system using dual cameras with different viewing angles [Huang 95, 96, 97]. One is a fixed camera having a wide viewing angle. Another one is a rotating narrow-viewing-angle camera to catch a small area of users' face. In our case, the target area is mouth part for detecting the utterance of the user.
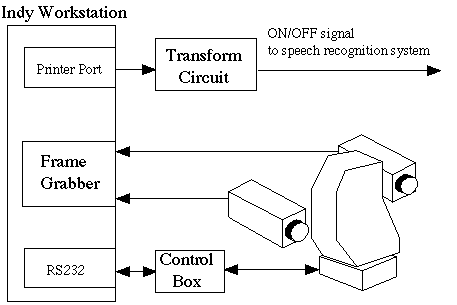

Fig. 9 A vision system with dual viewing angles.

Fig. 10 Tracking with dual viewing fields.
Figure 10 illustrates the result that, based on the location of the user detected by the fixed wide-view camera, the rotating narrow-view camera can successfully track the mouth part. Then, based on the analysis of the mouth region with a sufficient resolution, the utterance periods of the user are successfully extracted in real time as shown in Fig.11. This result is sent to the speech recognizer, which is activated to operate only during the utterance periods. Thus there is no need to use a switch operated usually by a user for indicating the utterance periods to the speech recognizer. In an experimental setting, successful realtime speech recognition has been achieved using this dual-camera vision system.
This dual-camera vision system is also useful for other purposes in human interface, such as for the detection of facial expression, etc.
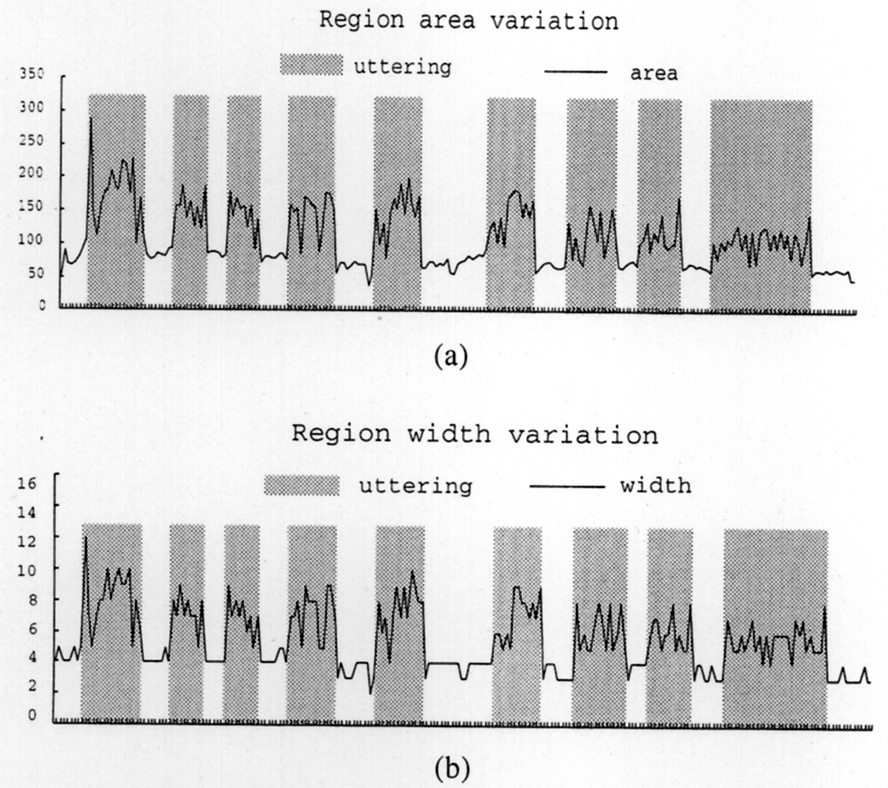
Fig. 11 Detection of utterance periods based on realtime analysis of mouth region.
3.4 Hair-Style Synthesis based on Wisp Model
A realistic facial image of the anthropomorphic agent is obtained by the texture mapping of a human facial image onto a 3D facial model. However, the appearance of hair has not been good enough in the texture-mapped facial image, while the hair is an important part particularly for women. We have thus developed a hair synthesis system with which we can produce a variety of hair styles for the anthropomorphic agent [Chen 99]. Figure 12 shows its overall picture.
Of course, there have been several researches on the synthesis of hair images in computer graphics field. Their methods are roughly classified into two categories, i.e., explicit model (including particle model) and volume density model. The former model treats the hair in micro-scopic ways; on the other hand, the latter model is macro-scopic. In our wisp model, an intermediate wisp unit is introduced to effectively manipulate a group of hairs, which are treated basically in a micro-scopic way within the wisp unit. This wisp model allows both high controllability of hair styles and high reality of the hair. Also, an animation of the hair is possible based on a pendulum model.
As shown in Fig. 13, trigonal-prisms are used to control the position of hair wisps. It is noted that the hairs are distributed outside the trigonal wisp area so that the discontinuity between the wisps does not appear. A fast rendering algorithm has been developed for this wisp model.
width="495" height="450"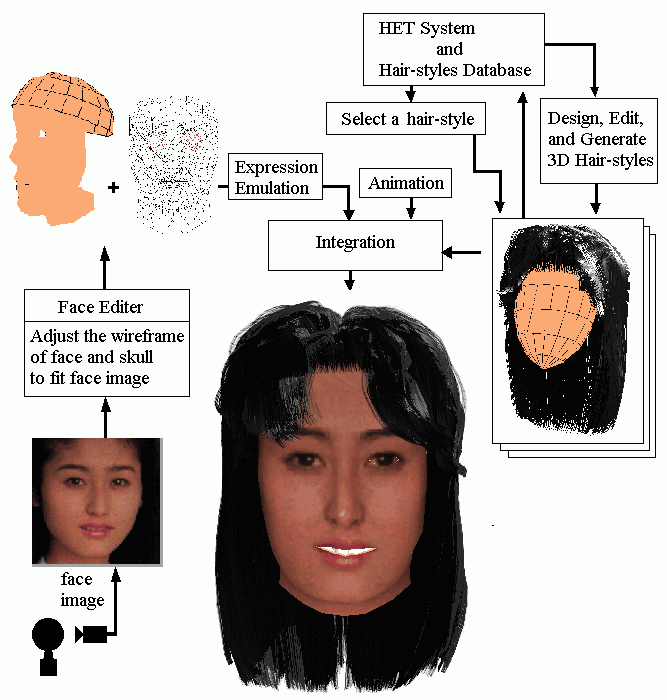
Fig. 12 Hair-style synthesis system based on wisp model.
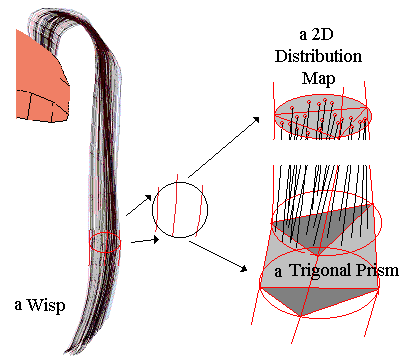
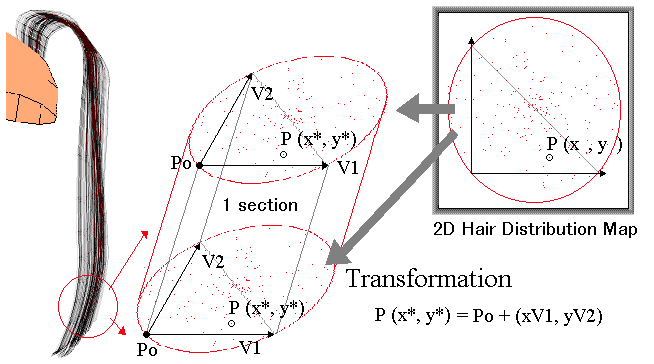
Fig. 13 Trigonal-prism wisp model and hair distribution map.
Figure 14 is a display image of an hair-style editor tool (HET) for designing various hair styles to be synthesized employing the wisp model. Some of synthesized hair styles are depicted in Fig. 15. Figure 16 shows four snapshots of a series of long hair movement produced by the pendulum model.
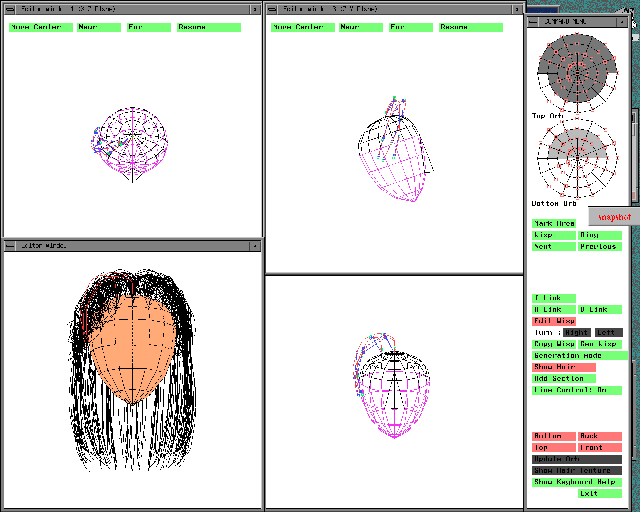
Fig. 14 Hair-style editor tool (HET).
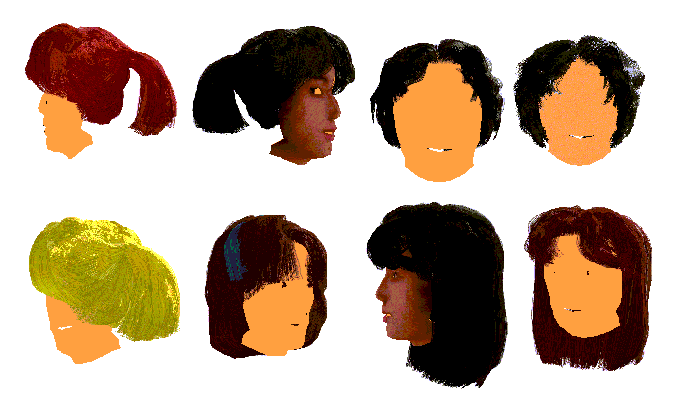
Fig. 15 Various hair styles and colors.
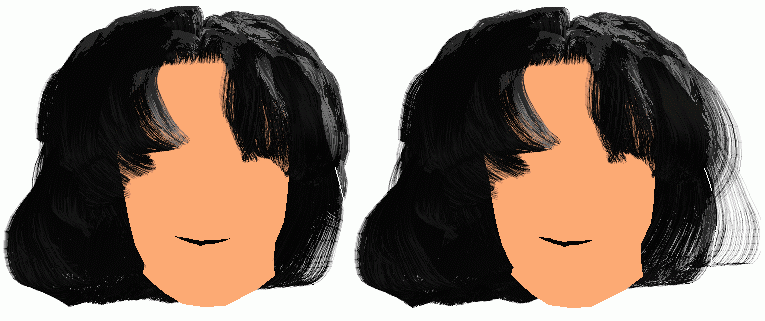
|
|||||||||||||||||||||||||||||||||||||||
| |
animation |
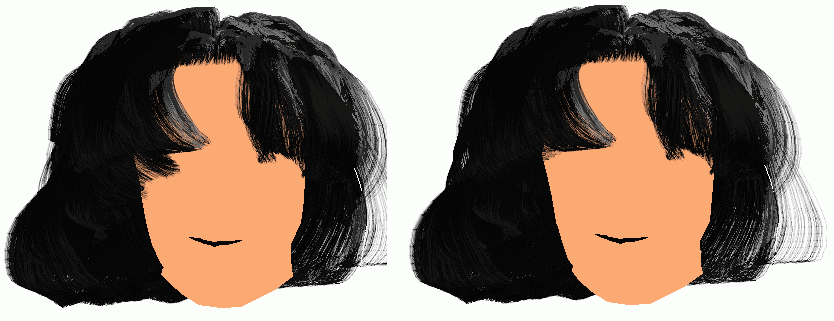
|
|||||||||||||||||||||||||||||||||||||
| Fig. 16 Movement with a pendulum model. |
|||||||||||||||||||||||||||||||||||||||
3.5 Learning of Cooperative Answering Strategy through Speech Dialogue
We have developed a learning function for the dialogue management module [Takama 97, 98] as shown in Fig.17. It learns cooperative answering rules through speech dialogues based on reinforced learning.
Before 1994, we were considering to use our VSA system as a visual agent guide system, for example, at a department store for replacing department guide girls. In that situation, the design of cooperative answering rules is not an easy task, because it highly depends on a specific location. Automatic learning or rule tuning may be an answer for this issue.
We have to consider the following dependencies.
* User dependency:
- individual user's knowledge about the domain.
- the context of the dialogue.
* Situation (Location) dependency:
- system's location.
- common characteristics of users at the place.
To cope with the former dependency, we employ a user model which holds facts and knowledge about a user acquired from preceding dialogue as in other dialogue management systems. To see the latter dependency, consider a typical question in a guidance system ?ell me the way to xxx· One answering strategy to this question is to explain a way from the location where the system is installed. Another strategy is to use an appropriate landmark. The selection of these strategies should be dependent on the user model and the common characteristics of users at the place of the system installed.
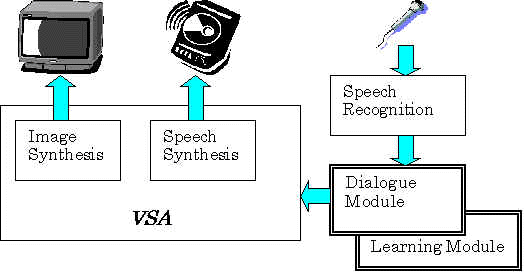
Fig. 17 Learning module for cooperative answering strategy
through speech dialogue.
--------------------------------------------------------------------------------------------------
Q1:"Where is (Place)?" ---------------------------------------------------------------------------------------------------Rule2: way from system's location to place. Q2:"Where is (Facility)?"
Rule3: use a landmark -- inadequate for type B &D.Rule4: way from system's location to facility's location Q3:"Where can I have lunch?"Rule5: landmark & way to facility's location -- sometimes inadequate -- sometimes inadequate
Rule6: building's name & way to facility's location.
Rule7: list all restaurants' names Q4:"Where can I have (Menu)?"
Rule8: suggest the restaurant nearest to the place user knows.
-- adequate for type C &D.
Rule14: restaurant's name Rule15: restaurant's name & its location
Fig. 18 Competing answering rules - examples.
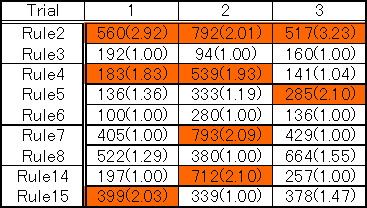
Figure 18 shows an example of answering rule patterns in an experimental campus guide system of the University of Tokyo. There are competing rules having priority weights. We used the profit sharing strategy of the reinforcement learning to learn the rule weights automatically through speech dialogues. The reward of the reinforcement learning was determined based on the number of utterance pairs (question-answer pairs) required to attain the user's goal of the dialogue. That is, the reward became large when the number of the utterance pairs was small to satisfy the user's goal.
There were 4 types of users, totally 16 users in an experiment. Table 1 illustrates the result of an experiment of the reinforcement learning, showing that the weights of appropriate rules have become approximately two-times larger than those of other rules in many cases. This was still a small experiment; however, it suggests that similar learning mechanisms are effective for automatically producing the behaviors of lifelike agents.
Table 1 Experimental result of the reinforcement learning of rule weights through speech dialogues.
3.6 Pan-tilt LC Display for Real Physical Eye Contact
Eye contact is an important factor in friendly communications. Using a fixed display, a true eye-contact effect cannot be achieved. Thus we have recently developed a pan-tilt LC display for real physical eye contact. Figure 17 shows its picture. Based on the recognition of the location of a user's face using a tracking CCD camera, a flat liquid-crystal (LC) display is driven to face to the user's face. As a result, the eye-contact is achieved physically. This moving pan-tilt LC display may be also useful to convey the emotional or non-verbal expression of the anthropomorphic agent.

Fig. 19 Pan-tilt LC Display for real physical eye contact.
4. VSA connected with WWW Browser
Before 1994, we constructed data and knowledge bases of guidance information for stores and our university campus for our VSA system [(for example) Mori 95]. However, the construction of attractive and meaningful databases was not an easy task.
With the advent of a Mosaic Web browser in 1994, we decided to connect our VSA with the Mosaic browser. The advantage is that we can access a vast Web information space through our VSA interface. Also, a standardized HTML format can be commonly used for expressing various information contents to be conveyed through our VSA.
Figure 20 shows a display of the VSA system connected with the Mosaic browser [Dohi 96a, 96b, 96d]. Anchor strings appearing in a Web page are automatically extracted and associated with index numbers, so that the index number can be used as a voice input to indicate a hyper-link going to next Web page. This function is necessary, since the voice recognizer cannot recognize all the anchor strings that appear in the Web pages, but can only recognize pre-registered word strings. In the left-lower window of Fig. 20, a list of the extracted anchor strings is displayed with the associated index numbers.
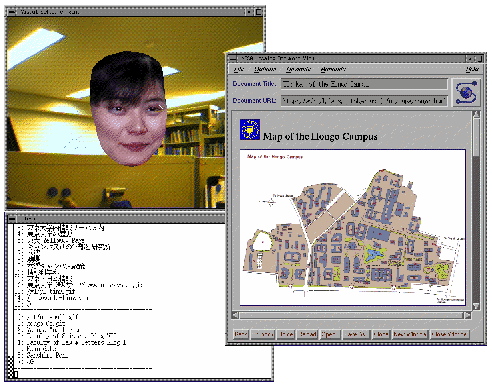
Fig. 20 VSA connected with Mosaic
1) Select-by-Keyword
(There are equivalent to click on the anchor "foo" which is pre-registered in the voice recognizer.)
(This provides a voice-based hotlist or bookmark function.)
(This function is used particularly for unregistered anchor strings and for image anchors.)
(These commands correspond to operate functional buttons in the menu bar of a Web browser.)
These voice commands and ordinary mouse operations are parallel and equivalent. That is, we can use either way at any time. The voice interaction with the Web information space is particularly useful when the mouse interface is not appropriate, for example, in the environment of using a wide screen display as shown in Fig. 21.
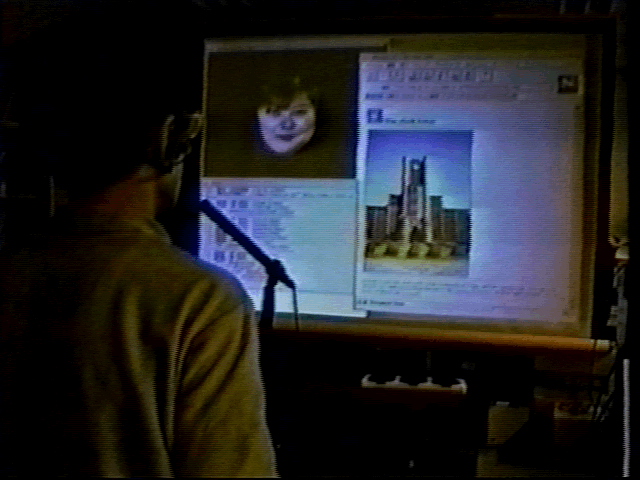
Fig. 21 Voice interaction with WWW via wide screen display.
There are some problems with the voice-controlled Web browser, such as,
- location-dependent anchors -- ex.) "here",
- anchors with an identical name,
- non-character (image) anchors,
- many anchors in a page.
This implies that only with voice it is unable to point the spatial location precisely. Some guidelines are required for voice-controlled Web pages.
For the Mosaic interface, we employed source-code level connection, since its source code (approx. 60,000 lines) was available. However, Mosaic became obsolete soon. Then we developed a Netscape interface in 1996 [Dohi 97a, 97b]. It's source code, however, was not available at that time. We thus employed a Proxy bypass technique to get necessary communication data between the Netscape browser and the network. There still remains a mismatch problem because the Netscape browser (and other browsers also) loosely accepts many types of non-standard tag descriptions (including erroneous descriptions) and the specification of the accepting range is not revealed. (In 1998, the source code of the Netscape browser becomes open. But, we have not taken any action to use it yet.)
Figure 22 is a display image of the VSA connected with the Netscape browser. The appearance and function of this VSA-Netscape system is almost the same as the previous VSA-Mosaic system.
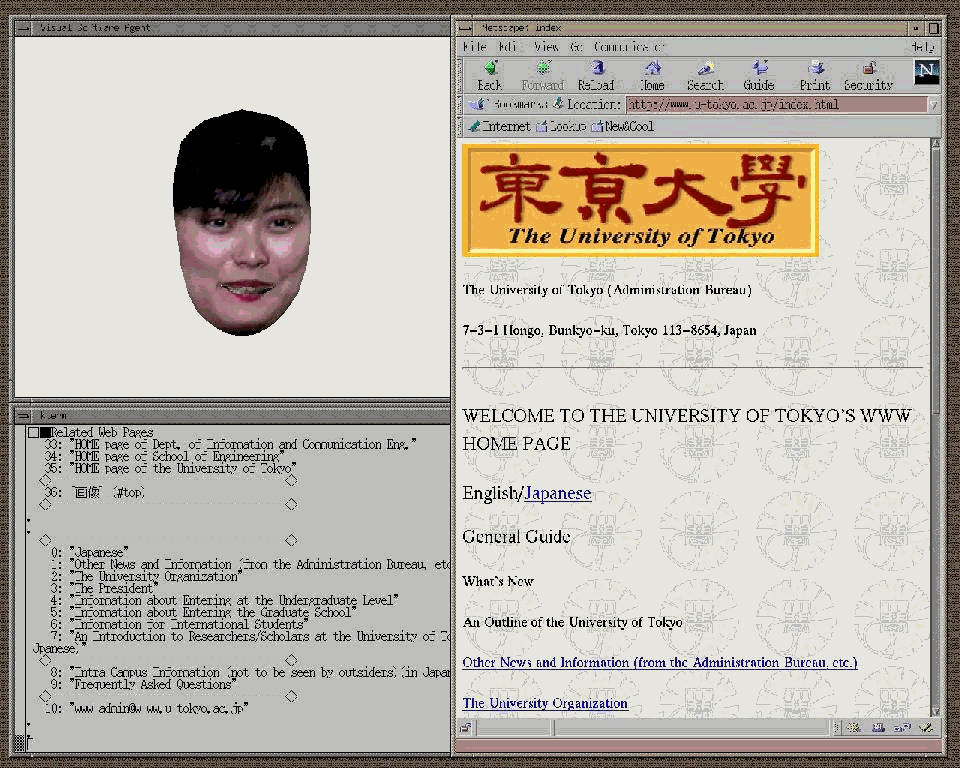
Fig. 22 VSA connected with Netscape.
Sub-agents are combined with the VSA-Netscape system as shown in Fig. 23. These sub-agents regularly collect useful information from the Web space and store them in a local database. As a result, the VSA can reply to users' common or frequent questions without the delay of the network, such as, about weather forecast and stock market information. Figure 24 shows the system configuration of the VSA-Netscape system, where six processes run concurrently. Thereby, speech input can be processed every timing.
The VSA-Netscape system is successfully running and providing us with a new multimodal interface to the WWW space. The following illustrates a simple dialogue example of the multimodal VSA-Netscape system.
VSA : Yes. Just a moment please.
User : Please show me "campus map"
VSA : Yes.
The performance of the voice input part is not necessarily sufficient at present particularly for unfamiliar users and needs to be improved.
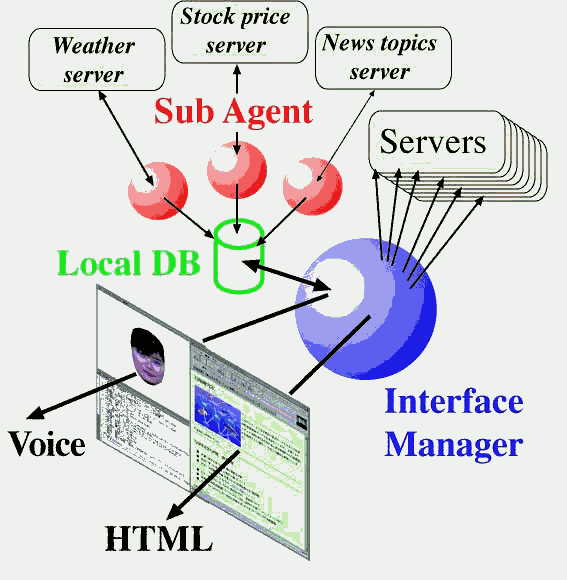
Fig. 23 Sub agents.
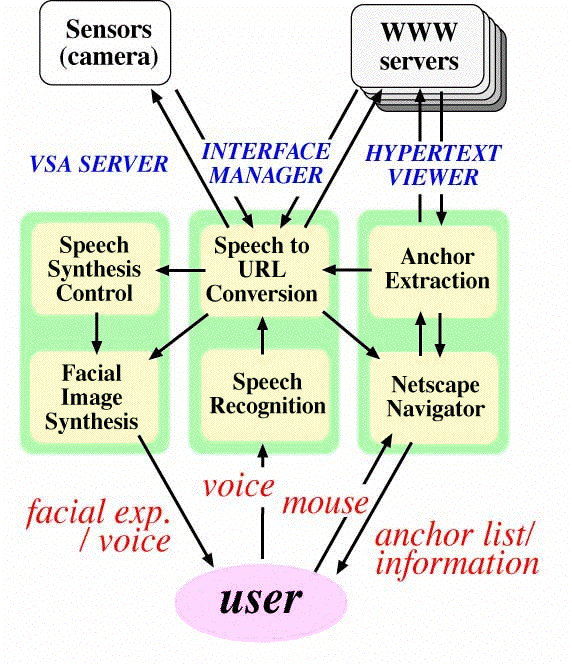
Fig. 24 System configuration of VSA-Netscape.
5. Visual Page Agent (VPA) as a Scheme of Making New Multimodal Web Contents
Recently, we have started to develop a Visual Page Agent (VPA) system. It aims at making new multimodal Web contents, not only a multimodal interface. A Page Agent exists or lives in a specific Web page and has knowledge and personality specific to the page. Its facial image changes quickly from page to page. VSA has been serving as a guide, secretarial assistant or mediator of the Web information space. On the other hand, VPA serves as an incarnation of the information holder himself/herself of the Web contents.
We are using realistic texture-mapped facial images for our VPA. It appears that the personality or identity of the author of the information content is becoming important nowadays to understand the content well among many other existing information contents. It is useful to distinguish trustworthy information in the information-overflowing society. Many articles and papers of journals include their authors' photographs. Beyond these authors' photographs, the authors' facial images of VPA have multimodal interactive functions; that is, they can provide multimodal presentations upon the requests of users and answer some questions. Therefore, we think the merit of our VPA will be recognized, which is different from other systems using cartoon-like characters.
The following VPA data are embedded in an HTML page under the tag of
< VSA = "URL of VPA data file">.
- 3D face model + 1 texture image (JPEG file)
- Voice attributes (Japanese/English, Female/Male, Pitch, Intonation, etc.)
- Message texts (1st message and reply message patterns)
- A correspondence table between voice keywords and URLs specific to
the individual page
(The anchor list is automatically produced and displayed as default, like VSA.)
When a Web page including the VPA tag is accessed, these data are downloaded to the VPA-Netscape system, which generates a realistic anthropomorphic agent specific to the page. Ordinary Web browsers ignore this tag and can work normally. Most parts of VPA software processes are common with VSA.
5. Entering 2nd Phase of Multimodal Interface Research
In 1998, Microsoft Corp. has released its agent system called Microsoft Agent in the market. It is well integrated tool for multimodal interfaces including agent characters and speech recognition/synthesis functions. Its main characters are shown in Fig.25. Other multimodal lifelike agent tools are also appearing. With the advent of these agent tools, the R&D of the multimodal agent interfaces seems to have entered into 2nd (practical) phase.



Fig. 25 Characters of Microsoft Agent.
As we stated above with respect to our VPA, we are recently interested in not only multimodal interface, but also making new multimodal attractive contents. One promising application is a multimodal presentation system with lifelike agent characters. It may allow multimodal presentations without human presenter. Many people may benefit from those presentations which are easily accessible through the network. One of its preferable technological properties is that it is fitted to current voice recognition technology, since its most part is voice output and a small set of voice commands will be accepted.
We are now developing technologies necessary to build such a multimodal presentation system employing our VSA/VPA, Microsoft Agent and other lifelike agents. Figure 26 is a snapshot of our prototype system using Microsoft Agent. This system can accept a small set of speech questions shown in the display, and answer them with speech outputs and the behaviors of the agent character.

<presen date="7/22/1998" place="Univ. of Tokyo, Eng-Bld-14">
<head repeart="1">
<agent player="VSA">
</agent>
<title id="tsutsui3" >
Proposal of PLM
</title>
</head>
<body>
<panel src="http://www.miv.t.u-tokyo.ac.jp/~tsutsui/presen/"/>
<text id="tt1" sync="no">
This is my presentation of our multimodal presentation mark-up language.
</text>
</body>
</presen>
</mpml>
Fig. 27 A simple example of MPML script.
To allow an easy and uniform high-level description for the multimodal presentations employing various lifelike agents, we are now designing and implementing MPML (multimodal presentation markup language) referring to XML and SMIL. SMIL is a synchronized multimedia integration language standardized in W3C. Figure 27 illustrates a simple MPML script description. As shown in Fig. 28, the MPML script is converted to operate our VSA/VPA, Microsoft Agent and other agent systems such as ASHOW of ETL and TVML of NHK and Hitachi.
With this tool, we expect that everyone will be to able to easily write his/her (interactive) multimodal presentations like writing HTML texts, and dispatch them through the WWW.
6. Related Work R&Ds on multimodal interfaces using
lifelike characters have been carrying out at several
universities, research institutes and companies, such as Univ. of
Tokyo, Toshiba, NEC, Sony, Hitachi, Electrotechnical Lab. (ETL),
Real-World Computing Project, ATR in Japan, and Stanford Univ.,
MIT's Media Lab., New York Univ., Microsoft in the United States.
In addition, presentation agent systems using lifelike characters
are being developed at Univ. of Pennsylvania, DFKI (Germany),
North Carolina State Univ. and USC Info. Sci. Institute. [Elliott
98] is a survey paper on these researches.
Commercial agent character tools available as
of 1998 are DECface/Face Works (DEC-Compaq), Microsoft Agent,
Jack (Transom Tech./Univ. of Pennsylvania) and an Extempo's agent
tool (with Stanford Univ.) Figure 28 shows the representative
agent characters of above system developments. Basic studies such as on psychological aspects,
emotional behaviors, etc., are also going on along with practical
developments. 7. Conclusion We have presented our VSA (visual software
agent), a multimodal anthropomorphic agent system, as a promising
new style of human interface beyond currently dominating GUI
style. It is realized as the integration of media, intelligence
and network technologies. In particular, we have emphasized the
importance of fusing with the evolving networked WWW information
environment. We are continuing our research along this direction. References
[Chen 99] L. H. Chen, S. Saeyor, H.Dohi and M. Ishizuka: A 3D Hair-Style
Synthesis Systembased on Wisp Model, (to appear) Visual Computer(1999)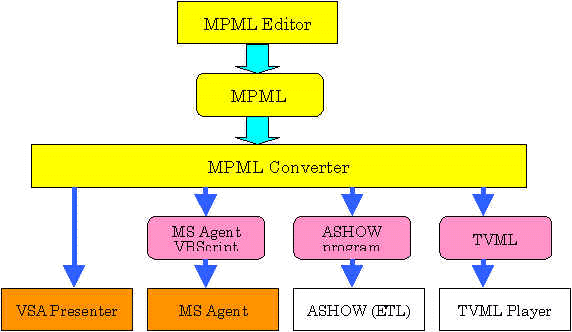






Fig. 29 Characters in various lifelike agent systems
[Dohi 93] H. Dohi and M. Ishizuka:
Realtime Synthesis of a Realistic Anthropomorphous Agent
toward Advanced Human-Computer Interaction, Proc.
HCI'93 (Human-Computer Interaction--Software and Hardware
Interfaces), Florida, pp.152-157 (1993)
[Dohi 96a] H. Dohi and M. Ishizuka: A
Visual Software Agent connected with the WWW/Mosaic, Proc.
Multimedia Japan '96 (MMJ'96), Yokohama, pp.392-397
(1996)
[Dohi 96b] H. Dohi and M. Ishizuka: A
Visual Software Agent: An Internet-Based Interface Agent
with Rocking Realistic Face and Speech Dialogue Function,
Working Note of AAAI-96 Workshop on Internet-Based
Information Systems, pp.35-40 (1996)
>
[Dohi 96c] H. Dohi, I. Morikawa and M.
Ishizuka: A Realtime Tracking Mechanism of User Movement
for Anthropomorphous Agent Interface (in Japanese), Jour.
of Inst. of Image Electronics Eng. of Japan, Vol.25,
No.2, pp.121-129 (1996)
>
[Dohi 96d] H. Dohi and M. Ishizuka: A
Visual Software Agent Connected to WWW/Mosaic (in
Japanese), Trans. IEICE D-II, Vol.J97-D-II, No.4,
pp.585-591 (1996)
[Dohi 97a] H. Dohi and M. Ishizuka:
Visual Software Interface with Realistic Face and
Voice-controlled Netscape, Proc. Int'l Conf. on
Computational Intelligence and Multimedia Applications
(ICCIMA'97), Gold Coast, Australia, pp.225-229 (1997)
[Dohi 97b] H. Dohi and M. Ishizuka:
Visual Software Agent: A Realistic Face-to-Face Style
Interface connected with WWW/Netscape, Proc. IJCAI-97
Workshop on Intelligent Multimodal Systems, pp.17-22,
Nagoya (1997)
[Elliott 98] C. Elliott and J.
Brzezinski: Autonomous Agents as Synthetic Characters, AI
Magazine, Vol.19, No.2, pp.13-30 (1998)
[Hasegawa 91] O. Hasegawa, W.
Wongwarawipat, C. W. Lee and M. Ishizuka: Real-time
Moving Human Face Synthesis using a Parallel Computer
Network, Proc. IECON '91, Kobe, pp.1330-1385
(1991)
[Hasegawa 92a] O. Hasegawa, C. W. Lee,
W. Wongwarawipat and M. Ishizuka: A Realtime Visual
Interactive System between Finger Signs and Synthesized
Human Facial Images employing a Transputer-based Parallel
Computer, Visual Computing (T.L.Kunii (ed.)),
Springer-Verlag, pp.77-94 (1992)
[Hasegawa 92b] O. Hasegawa, C. W. Lee,
W. Wongwarawipat and M. Ishizuka: Realtime Synthesis of
Moving Human-like Agent in Response to User's Moving
Image, Proc. ICPR'92, Hagne, Vol.IV, pp.39-42
(1992)
[Hasegawa 93] O. Hasegawa, K. Yokosawa,
M. Fujiki and M. Ishizuka: Realtime Facial Image
Recognition in Unconstrained Environment for Interactive
Visual Interface, Proc. Asian Conf. on Computer Vision,
Osaka, pp.763-766 (1993)
[Hasegawa 94a] O. Hasegawa, K. Yokosawa
and M. Ishizuka: Real-time Parallel and Cooperative
Recognition of Facial Images for an Interactive Visual
Human Interface, Proc. ICPR'94, Israel, Vol.III,
pp.384-387 (1994)
[Hasegawa 94b] O. Hasegawa, K. Yokosawa
and M. Ishizuka: Realtime Parallel and Cooperative
Recognition of Human Face for a Naturalistic Visual Human
Interface (in Japanese), Trans. IEICE D-II,
Vol.J77-D-II, No.1, pp.108-118 (1994)
[Hasegawa 95] O. Hasegawa, C. W. Lee,
W. Wongwarawipat and M. Ishizuka: Real-time Synthesis of
a Human Agent in response to the User's Moving Image, Machine
Vision and Applications, Springer-Verlag, Vol.8,
pp.122-130 (1995)
[Hiramoto 94] Y. Hiramoto, H. Dohi and
M. Ishizuka: A Speech Dialogue Management System for
Human Interface employing Visual Anthropomorphous Agent, Proc.
RO-MAN'94 (IEEE Workshop on Robot and Human
Communication), Nagoya, pp.277-282 (1994)
[Huang 95] Y. J. Huang, H. Dohi and M.
Ishizuka: A Realtime Visual Tracking System with Two
Cameras for Feature Recognition of Moving Human Face, Proc.
RO-MAN'95 (IEEE Workshop on Robot and Human
Communication), Tokyo, pp.170-175 (1995)
[Huang 96] Y. J. Huang, H. Dohi and M.
Ishizuka: A Vision System with Dual Viewing Angles for
Spontaneous Speech Dialogue Environment, Proc. IAPR
Int'l Workshop on Machine Vision Applications (MVA'96),
Tokyo, pp.229-232 (1996)
[Huang 97] Y. J. Huang, H. Dohi and M.
Ishizuka: Man-Machine Interaction using a Vision System
with Dual Viewing Angles, IEICE Trans. Inf. &
Syst., Vol.E80-D, No.11, pp.1074-1083 (1997)
[Ishizuka 91] M. Ishizuka, O. Hasegawa,
W. Wongwarawipat, C. W. Lee and H. Dohi: Visual Software
Agent (VSA) Built on Transputer Network with Visual
Interface, Proc. Computer World '91, Osaka,
pp.36-46 (1991)
[Ishizuka 93] M. Ishizuka: Fusing Media
and AI Technologies (in Japanese), Jour. of Japanese
Soc. for AI, Vol.8, No.6, pp.819-827 (1993)
[Kawamura 95] T. Kawamura, H. Dohi and
M. Ishizuka: Realtime CG Animation of Realistic Fishes
using NURBS, Inverse Kinematics and a Co-operative Motion
Model, Proc. Int'l Conf. on Virtual Systems and
Multimedia (VSMM'95), Gifu, pp.260-265 (1995)
[Kay 84] A. Kay: Computer Software, Scientific
American, Vol.251, No.3, pp.52-59 (1984)
[Laurel 90] B. Laurel: Internet Agent:
Metaphors with Character, The Art of Human-Computer
Interface Design (B. Laurel (ed.)), pp.355-365,
Addison-Wesley (1990)
[Mori 95] M. Mori, H. Dohi and M.
Ishizuka: A Multi-purpose Dialogue Management System
employing Visual Anthropomorphous Agent, Proc.
RO-MAN'95 (IEEE Workshop on Robot and Human
Communication), Tokyo, pp.187-192 (1995)
[Takama 97] Y. Takama, H. Dohi and M.
Ishizuka: Automatic Learning of Cooperative Answering
Strategy through Speech Dialog in Visual Anthropomorphous
Agent (in Japanese), Jour. of Japanese Soc. for AI,
Vol.12, No.3, pp.456-465 (1997)
[Takama 98] Y. Takama, H. Dohi and M.
Ishizuka: A Visual Anthropomorphic Agent with Learning
Capability of Cooperative Answering Strategy through
Speech Dialog, Proc. Asia Pacific Computer Human
Interaction (APCHI'98), pp.260-265, Japan (1998)
[Wongwarawipat 90] W. Wongwarawipat and
M. Ishizuka: A Visual Interface for Transputer Network
(VIT) and its Application to Moving Image Analysis,
Transputer/Occam Japan 3 (T. L. Kunii, D. May
(eds.)), IOS Press, pp.65-75 (1990)
[Wongwarawipat 91] W. Wongwarawipat, C.
W. Lee, O. Hasegawa, H. Dohi and M. Ishizuka: Visual
Software Agent Built on Transputer Network with Visual
Interface, Transputing '91 (Proc. Int'l Conf. on
Transuputing), Sunnyvale, pp.818-827 (1991)
[Yamauchi 94] Y. Yamauchi, H. Dohi and
M. Ishizuka: A Visual Software Robot with Automomous
Distributed Behavior Model Implemented on a
Transputer-based Parallel Computer, Transputer/Occam
Japan 6 (S. Noguchi, M. Ishizuka, M. Ohta (eds.)),
(Proc. 6th Transputer/Occam Int'l Conf.), IOP Press,
pp.288-299 (1994)